新建表 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
CREATE TABLE ` user ` (
` id ` int ( 11 ) NOT NULL AUTO_INCREMENT COMMENT '自增主键' ,
` uname ` varchar ( 100 ) NOT NULL DEFAULT '' COMMENT '姓名' ,
` nickname ` varchar ( 255 ) NOT NULL DEFAULT '' COMMENT '昵称' ,
` phone ` char ( 11 ) NOT NULL DEFAULT '' COMMENT '电话' ,
` emp_no ` varchar ( 20 ) NOT NULL DEFAULT '' COMMENT '员工编号' ,
` dept_id ` int ( 4 ) NOT NULL DEFAULT '0' COMMENT '部门id' ,
` pwd ` varchar ( 255 ) NOT NULL DEFAULT '' COMMENT '密码' ,
` avt ` varchar ( 255 ) NOT NULL DEFAULT '' COMMENT '头像' ,
` addr ` varchar ( 255 ) NOT NULL DEFAULT '' COMMENT '地址' ,
PRIMARY KEY ( ` id ` ),
KEY ` index_user ` ( ` dept_id ` , ` uname ` , ` phone ` ) USING BTREE ,
KEY ` avt ` ( ` avt ` ),
KEY ` emp_no ` ( ` emp_no ` ),
KEY ` index_nickname ` ( ` nickname ` , ` pwd ` ) USING BTREE ,
KEY ` addr ` ( ` addr ` ) USING BTREE
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4 ;
最左原则 1
2
3
4
5
6
7
8
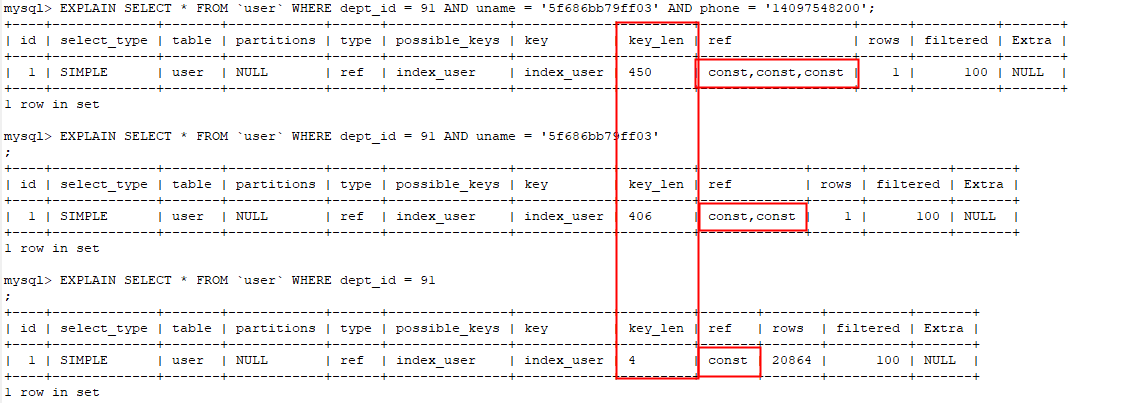
SELECT
*
FROM
` user `
WHERE
uname = '5f686bb79ff03'
AND dept_id = 91
AND phone = '14097548200' ;
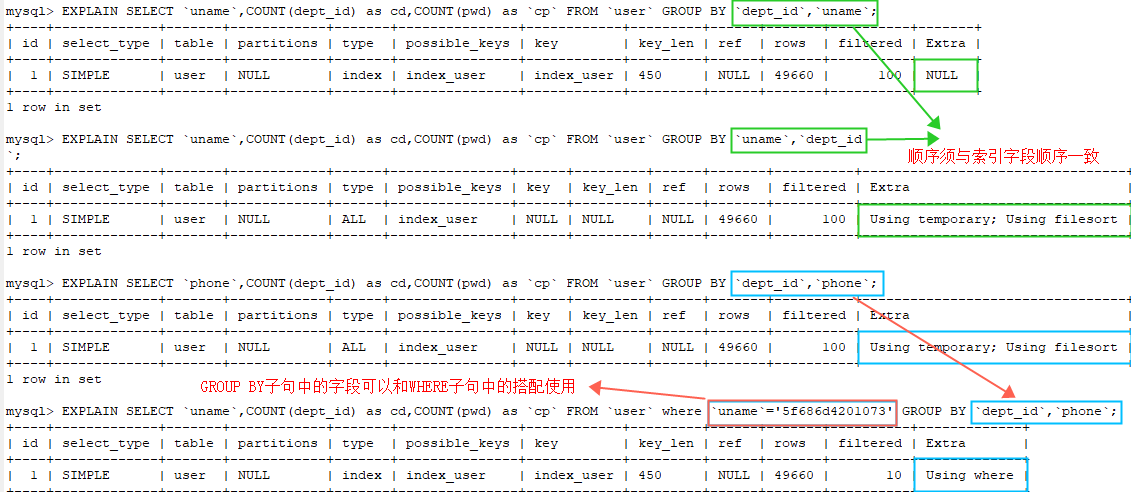
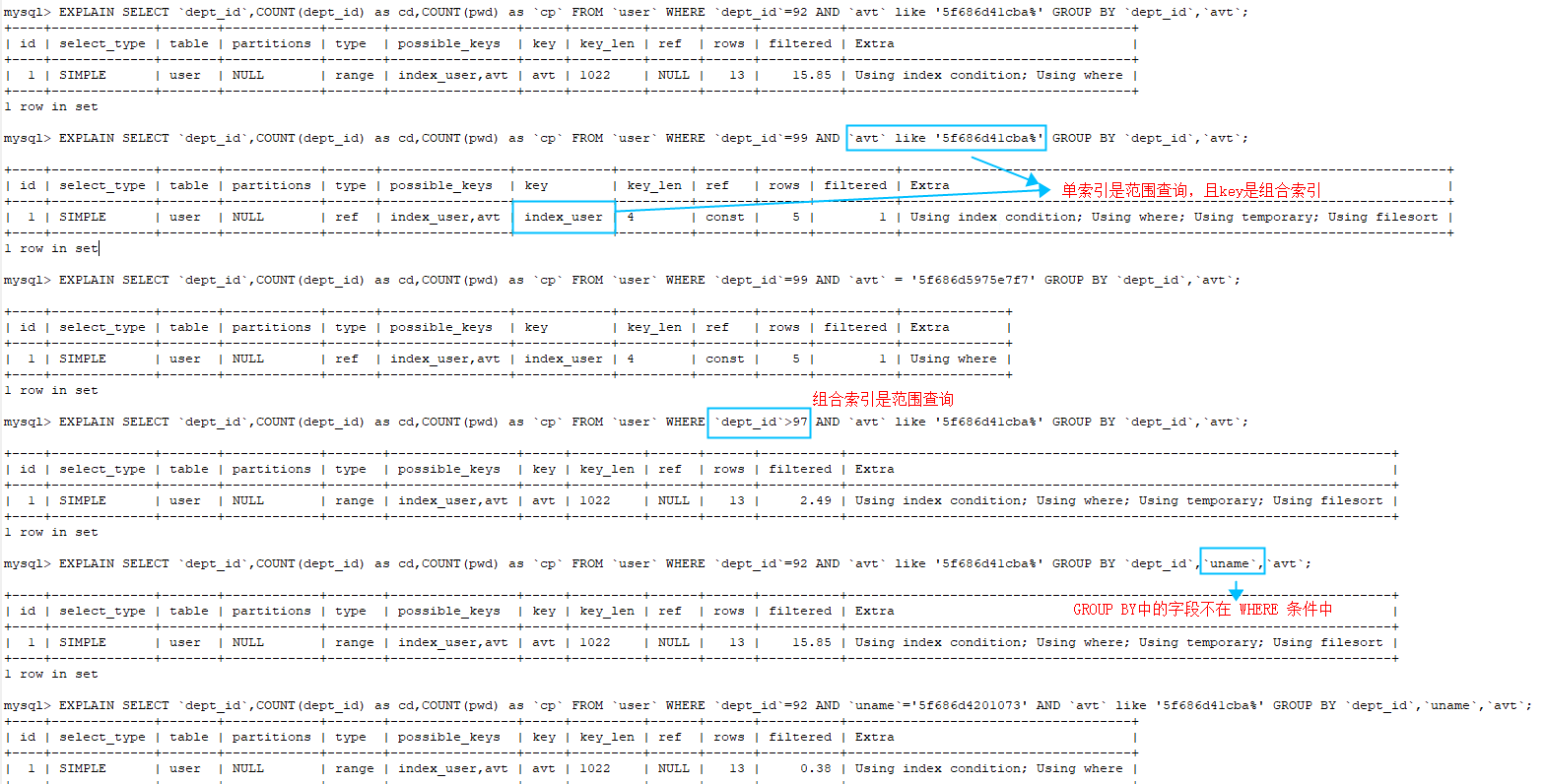
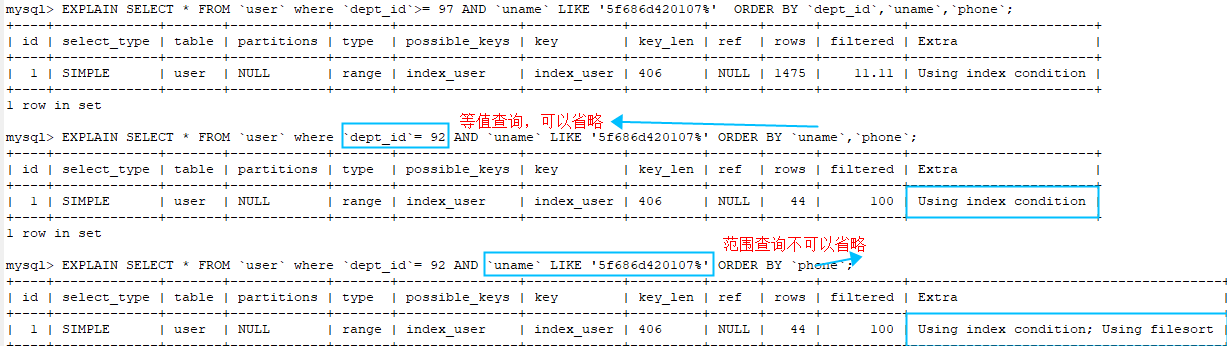
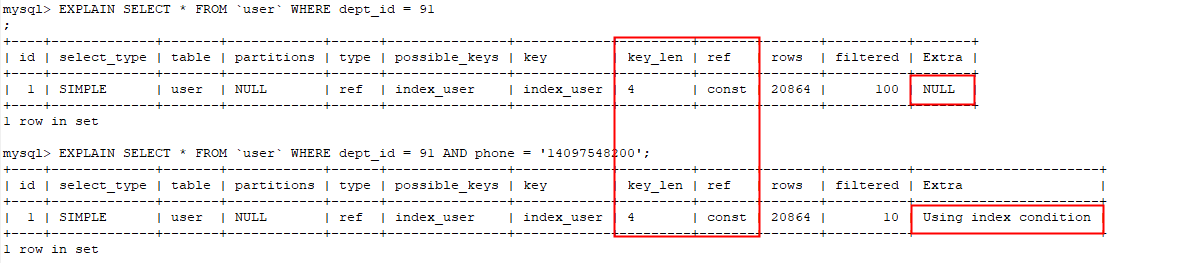
MySQL学习笔记:组合索引-最左原则 where子句中,只能按照索引字段,从右向左依次截取字段,剩下的字段依次作为有效索引 1
KEY ` index_user ` ( ` dept_id ` , ` uname ` , ` phone ` ) USING BTREE
可以直接用的有效索引有:(dept_id,uname,phone),(dept_id,uname),(dept_id)
MySQL学习笔记:组合索引-最左原则 (dept_id,phone)中phone是走不上索引的,但是当满足MySQL的索引下推条件时,是可以减少回表次数,从而减少查询时间的。
MySQL学习笔记:组合索引-最左原则